

Guide to Q-Learning
January 10, 2025

Welcome to our Q-Learning tutorial! This guide provides an in-depth look at Q-Learning, a model-free reinforcement learning technique that empowers intelligent agents to learn optimal strategies in complex, dynamic environments. Whether you're new to reinforcement learning or looking to refine your knowledge, this tutorial has something for you.
In This Tutorial, We Cover:
- Introduction to Q-Learning: Understand what Q-Learning is and how it fits into the world of reinforcement learning.
- True Learning and Decision Making: Discover how Q-Learning agents make decisions based on rewards and future outcomes.
- Supervised vs. Unsupervised Learning: Explore the key differences between supervised and unsupervised learning, and why Q-Learning is ideal for environments requiring adaptability and long-term optimization.
- Q-Table Representation: Learn how Q-Tables are used to store and update an agent’s knowledge about actions and states, helping it make informed decisions over time.
- Visualization and Dataset Overview: Get an overview of the dataset used and how to visualize it for better understanding and learning.
- Creating the Churn Prediction Environment: Walk through how to set up a custom environment, such as a churn prediction model, to train your Q-Learning agent.
- Initializing Learning Parameters: Learn how to define and initialize key parameters like the learning rate and discount factor that guide the agent’s learning process.
- Training the Learning Agent: Dive into the practical steps of training your Q-Learning agent, observing how it improves decision-making over time.
Introduction
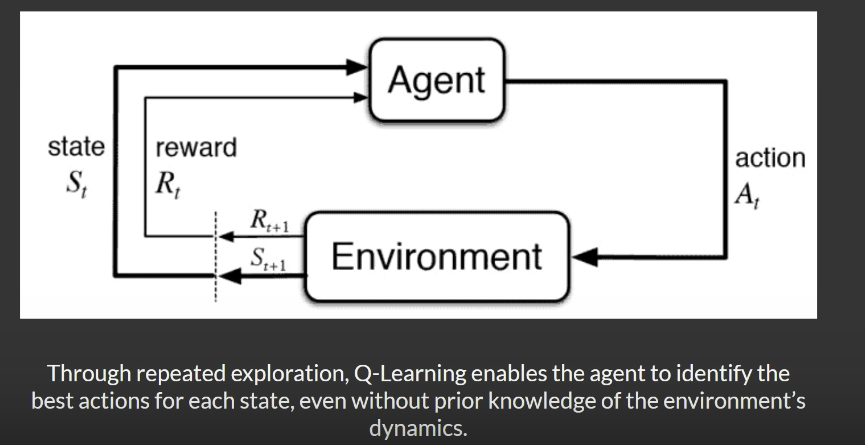
Q-learning is a key concept in Reinforcement Learning (RL), a fascinating branch of Machine Learning (ML). While traditional ML focuses on teaching computers to learn patterns from data, RL takes a different approach—it trains agents to make decisions by interacting with an environment to achieve a specific goal.
What Makes Q-Learning Unique?
Q-learning stands out as one of the first model-free reinforcement learning algorithms. Being model-free means the algorithm doesn’t need prior knowledge about the environment’s rules or dynamics—it learns solely through trial and error. This ability to adapt without predefined models makes Q-learning versatile and widely applicable.
Where does Q-learning fit in?
Imagine teaching a robot to play a game. At first, the robot knows nothing about the rules or strategies. Through trial and error, it learns by receiving feedback:
- Rewards for good moves.
- Penalties for bad moves.
The robot’s goal is to develop a strategy—known as a policy—that maximizes its total rewards over time. Q-learning is the technique that helps the robot estimate the value of each possible action in a given situation.
The "Q" in Q-Learning
The "Q" in Q-learning stands for Quality, referring to how beneficial a particular action is in a given state. To make this determination, the agent maintains a Q-table, essentially a cheat sheet where:
- Rows represent all possible states (e.g., the current situation in the game).
- Columns represent all possible actions (e.g., moves the robot can make).
- Cells contain Q-values, which indicate the long-term benefit of taking a specific action in a particular state.
How the Q-Table is Updated
The Q-values are refined over time using a formula that combines:
- Current reward: Immediate feedback for an action.
- Future rewards: The potential benefits of future actions.
Over time, the agent refines the Q-values to learn the best possible actions in every situation, achieving the optimal policy.
Predecessors of Q-learning
To better understand Q-learning, let’s compare it with other machine learning approaches:
Supervised Learning
- How it works: Models learn from labeled data to predict outcomes (e.g., fraud detection).
- Limitations: Effective for classification and regression but unsuitable for scenarios with unknown or evolving outcomes.
Unsupervised Learning
- How it works: Models uncover hidden patterns in unlabeled data (e.g., customer segmentation).
- Limitations: Great for exploratory analysis but incapable of handling sequential decision-making.
Reinforcement Learning
- How it works: Agents learn by interacting with the environment and maximizing cumulative rewards (e.g., robots navigating warehouses).
- Advantages: Designed for sequential, goal-oriented tasks, making it the ideal foundation for Q-learning.
How Does Q-learning Work ?
Q-learning involves a systematic process for learning the optimal policy through interaction with the environment.
- Initialize Q-Table: Start with a table where every state-action pair has an initial value, often zero.
- Agent Takes Action: The agent selects an action using an exploration-exploitation trade-off:
- Exploration: Try random actions to discover new strategies.
- Exploitation: Use the best-known actions based on the current Q-table.
- Receive Reward: After each action, the environment provides feedback—positive or negative—based on the action's outcome.
- Update Q-Table: Update the Q-value for the action using the Bellman Equation :
- Q(s,a) ← Q(s,a) + α[r + γ max Q(s',a') - Q(s,a)]
Where:
- Q(s,a): Current Q-value for the state-action pair.
- α: Learning rate, which controls how much new information overrides old.
- r: Reward for the current action.
- γ: Discount factor, determining the importance of future rewards.
- maxQ(s′,a′)\max Q(s', a')maxQ(s′,a′): Maximum Q-value for the next state-action pair.
- Blend current knowledge with new rewards and expected future rewards.
- Repeat Until Convergence: The agent continues to interact with the environment, updating Q-values until they stabilize, indicating the agent has learned the best policy.
Code Implementation and Case study
We use the telecommunications dataset, specifically the Customer churn prediction using Telecommunications data , provided by IBM sample data sets.
This dataset contains information about customers of a telecommunications company, including demographic details, account information, and service usage patterns. The primary goal is to predict whether a customer is likely to churn (leave the service) or stay. By analyzing this data, companies can better understand customer behavior and take proactive steps to reduce churn.
Downloading and Understanding the Dataset
Let's start with downloading and understanding the dataset.
We first install all the dependencies:
Next, we have a look at the data:
The dataset contains various features, including gender (male or female) and several categorical values such as online backup, data protection, and contract types (month-to-month or year-to-year). These categorical values will need to be converted or encoded into numerical values for analysis. Additionally, the dataset includes numerical features like tenure, monthly charges, and total charges. The target variable for prediction is whether a customer has churned or not.
Let’s do some quick EDA on the data set. We have all this information on the data set:
Visualizing numerical features:
Visualizing categorical features:
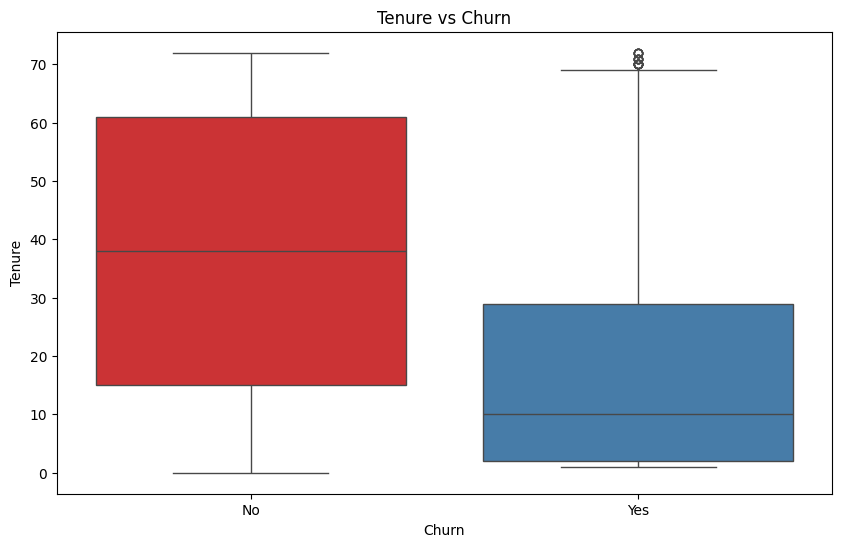
Visualizing the relationship between tenure and churn:
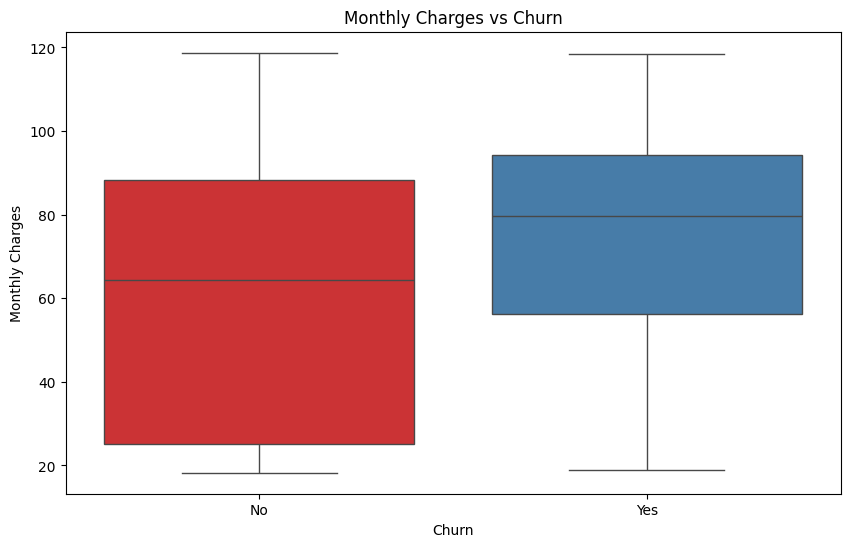
Visualizing the relationship between Monthly Charges and churn
We can also see the distribution, which is fairly complex:
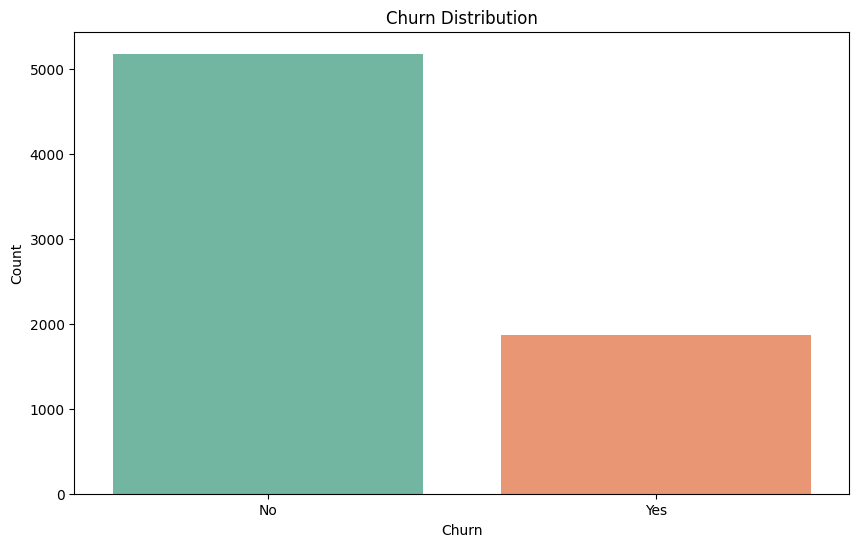
Next, we observe the churn distribution in the dataset. Approximately one-third of the customers have left the service, while the number of customers who did not churn is roughly three times higher.
We have the tenure versus churn distribution:
And We have monthly charges versus churn distribution.
Next, we move on to data preprocessing.
Data Preprocessing
We start by converting the categorical values into numerical values using a label encoder. The label encoder assigns unique integer values to each category, effectively transforming them into numerical representations.
We scale the numerical features to a range of 0 to 1, which is more suitable for the Q-learning agent. The churn value, however, is excluded from this scaling process.
We load and process the data:
After processing the data, all features are now numerical, and the customer identification column has been dropped. The dataset is fully scaled and encoded, and the churn data is ready for analysis.
For splitting the data into training and testing sets, we use a stratification technique. Stratification ensures that the proportion of the true label distribution (e.g., churned to not churned) is preserved in both the training and testing datasets. For instance, if the churned-to-not-churned ratio is 1:3, this ratio will remain consistent in both splits. This approach is particularly useful for imbalanced datasets, though more advanced techniques can also be applied.
The Softmax function:
Defining Q-learning agent class
Defining the Q-learning agent class begins with setting up a churn environment, which serves as the environment the agent will interact with.
In the constructor, we initialize the data values and the state dimensions. The state dimensions represent the features that the agent will observe. Specifically, we use the dataset's columns, excluding the policy data (indicated by data columns -1).
Next, we calculate the class weights. It is important to emphasize that misclassifying churners should be penalized more heavily than misclassifying non-churners. To address this, the weights are assigned dynamic values rather than static ones, ensuring appropriate punishment for errors based on the class imbalance.
We extract the state features, which convert the features of any given state into a vector representation. This allows the agent to process and learn from the state more effectively.
Next, we define the reset function, which initializes the environment at the beginning of each episode. It resets the done flag, indicating whether the training for the current episode is complete, and sets the current state to 0.
We define the step function, which executes an action based on the agent's current state. The action the agent takes—whether to retain or not retain a customer—is determined by evaluating the features in the current environment.
The reward system:
Let’s break this down in more detail:
- If the agent decides to retain the customer and the actual outcome is also retention (strength is 1), we assign a positive reward of 5, weighted by the class. This reflects a correct prediction of no churn.
- If the agent decides to retain the customer, but the customer actually churns (strength is 0), a negative reward of -2 is given to penalize the incorrect decision.
- If the agent decides not to retain the customer (no action), and the actual outcome is no churn (strength is 0), a positive reward of 2 is given. However, if the customer actually churns (strength is 1), a negative reward of -5 (weighted penalty) is applied for missing the churn.
After this, we calculate the next state based on the state dimensions. The done flag is used to indicate whether the episode has ended or not.
Now, we get on to the Q-Learning agent.
The __init__ function has multiple parameters:
- state_dim: Represents the dimensionality of the state space, i.e., the number of features per customer.
- action_size: The number of possible actions the agent can take (in this case, 2 actions: retain or no action).
- learning_rate: Determines how much the agent updates its Q-values after each action. A typical default is 0.05.
- discount_factor: The agent’s consideration of future rewards, indicating how much weight it gives to long-term rewards. A common value is 0.99.
- epsilon: Represents the exploration factor in the epsilon-greedy strategy. It controls the degree of randomness in action selection to ensure that the agent tries different actions. The default value is 1.0.
Initially, the epsilon value is set to 1, meaning that the agent will focus heavily on exploration. At the start of the Q-learning training, the agent should explore various actions to gather sufficient information. As the agent learns and updates its Q-table over time, the epsilon value gradually decreases towards a minimum of 0.15, following a decay factor of 0.999. By the end of the training, the agent will rely more on exploitation, using the knowledge it has gained to make the best possible decisions.
Discretization of the state:
The Q-table serves as a map that stores the Q-values for each state-action pair, essentially indicating the expected reward for taking a particular action in a given state. However, as state spaces grow larger, this can lead to significant space complexity. To manage this, we convert continuous customer features into discrete bins, reducing the size of the state space. Alternatively, we can use Deep Q-Learning, which employs neural networks to directly map raw features to actions, bypassing the need for a Q-table.
Now, based on the current state, the agent will select an action using the epsilon-greedy policy, which balances exploration and exploitation.
We update the Q-table. This is where the Bellman Equation comes in:
We update the Q-table using the Bellman equation and also update the Epsilon values.
Now we train the Q-learning agent:
Now, the agent will select an action based on its current state. Once the action is chosen, it will be passed into the step function, where the environment will process it and return the next state the agent enters.
The below code tracks the agent's performance, ensuring whether the prediction made by the agent is equal to the current actual true labels.
We also track the episode accuracy and rewards in the form of lists. This allows us to evaluate and compare the agent's performance over time to determine whether it is effectively learning.
As training progresses, the agent gradually reduces its exploration (randomness in action selection) and begins to rely more on exploiting the learned policy to make decisions.
At the end of the training, the agent will return the rewards history and the accuracy history, which can be used to visualize and assess the results.
Below is the function of visualization of the results.
We have two plots:
- The first plot represents the learning process, showing the reward. As the agent continues learning over time, the reward should stabilize, indicating that the agent is improving its decision-making.
- The second plot tracks the accuracy progression, which reflects the balance between exploration and exploitation. Over time, this plot should also stabilize and plateau, signaling that the agent is successfully exploiting its learned policy.
Learning process
Accuracy progression:
The evaluate model function is for running the tests on unseen data:
Now we start with initializing the environment and agent:
We begin training the agent:
Note: This particular piece of code takes around 15 minutes to execute.
You can observe that the epsilon value has decreased from 1. Initially, the total rewards start from a negative value, indicating that the agent was performing poorly. However, over time, the rewards gradually increase, reaching a final value of 23,506, showing that the agent is learning and improving its performance.
Visualizing the results:
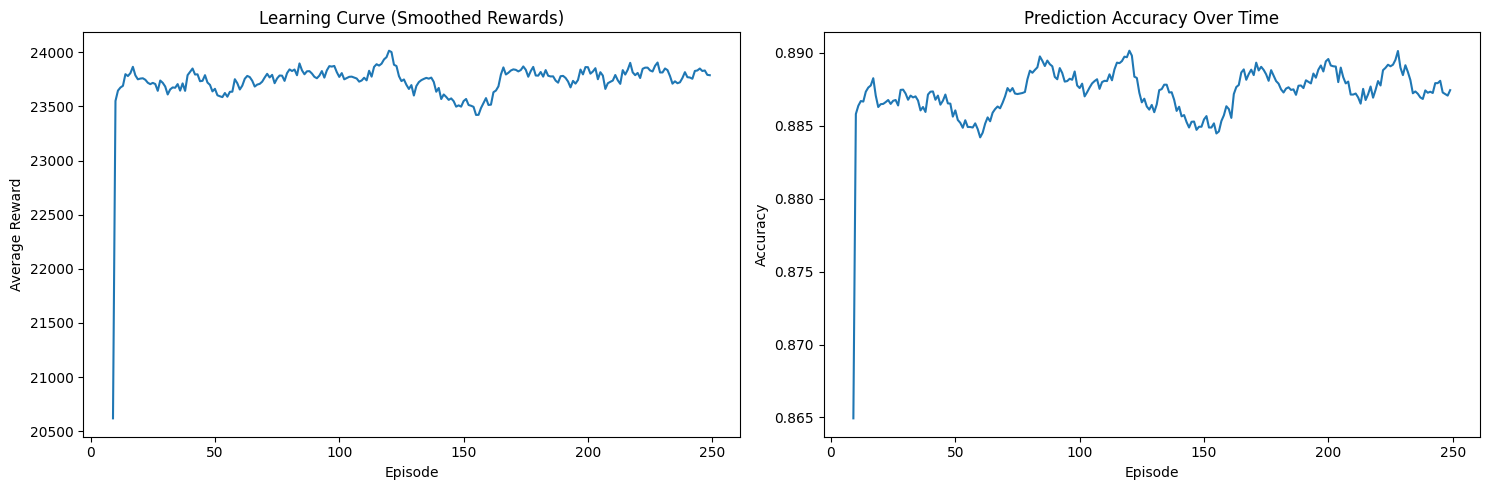
Visualizing the results, we notice a sharp spike in rewards from 20,000 to 23,000, indicating that the agent is learning rapidly. After that, the epsilon decreases, and the rewards start to stabilize, flattening over time. The same pattern is observed in the prediction values: initially, the agent's predictions were poor, but as training progressed, its predictions improved, especially on the unseen labels.
Next, we will run an evaluation on the unseen dataset:
We have the confusion matrix, AUC score, true positives, false positives, false negatives, and all relevant business metrics, as shown here:
As seen in the results, due to the imbalanced nature of the data, minimal preprocessing was done. Despite this, the agent still produced fairly good results. We have the confusion matrix, and it's important to note that you can adjust the learning rate and preprocessing steps to help the agent learn more effectively.
The training results demonstrate classic Q-learning behavior through two key visualizations:
- Smoothed Rewards Curve :
- Initial spike from ~21,000 to ~23,500 in the first few episodes shows rapid initial learning
- Quick convergence to a stable range between 23,500-24,000 after episode 50
- Consistent performance with minor fluctuations throughout training
- The stability of rewards after convergence indicates the agent has found a robust policy
- Prediction Accuracy Over Time :
- Dramatic improvement from 68% to ~89% accuracy in the first 10 episodes
- Sustained accuracy around 88-89% throughout training
- Small variations (±1%) indicate continued exploration while maintaining strong performance
- The high sustained accuracy suggests effective balance between exploration and exploitation
Time Complexity
- Per step: O(1) for Q-table lookup and update
- Per episode: O(n) where n is number of training samples
- Total: O(n * episodes)
Space Complexity
- Q-table: O(|S| * |A|) where |S| is number of visited states and |A| is the number of actions (2 in this case).
- The space complexity is bounded by the number of discretized states (n_bins^n_features * n_actions).
In this tutorial, we explored multiple case studies and visualizations to understand how Q-learning works. We covered both the theoretical and mathematical aspects, and we also saw the coding efficiency and practical implementation of Q-learning
What comes after Q-learning ?
- The most significant advancement following Q-Learning is Deep Reinforcement Learning (DRL), which combines reinforcement learning with deep learning techniques.
Key Features of DRL:
- Neural Networks for Function Approximation: DRL replaces the Q-table with a deep neural network to estimate Q-values, enabling it to handle complex environments with large state-action spaces.
- Learning from Raw Inputs: Unlike Q-learning, which often requires manually designed features, DRL can learn directly from raw data such as images or sensor readings.
- Handling Continuous Action Spaces: DRL excels in environments with continuous or high-dimensional action spaces, making it suitable for applications like robotics, self-driving cars, and game-playing agents.
A prime example of DRL is AlphaStar, developed by DeepMind, which mastered the complex game StarCraft II by processing high-dimensional state information using deep learning. This approach enabled AlphaStar to learn sophisticated strategies and outperform human players.
3. Multi-Agent Reinforcement Learning (MARL), which focuses on the interactions of multiple agents, and meta-learning, where agents learn to adapt their learning strategies. These advancements will enhance the adaptability and efficiency of RL algorithms, paving the way for applications across various fields, including robotics, healthcare, and personalized recommendations.
Present and Future Applications :
- A great example is the use of AI agents by Deepmind to cool Google Data Centers. This led to a 40% reduction in energy spending. The centers are now fully controlled with the AI system without the need for human intervention.
- IBM for example has a sophisticated reinforcement learning based platform that has the ability to make financial trades. It computes the reward function based on the loss or profit of every financial transaction.
- In this paper, the authors propose real-time bidding with multi-agent reinforcement learning. The handling of a large number of advertisers is dealt with using a clustering method and assigning each cluster a strategic bidding agent. To balance the trade-off between the competition and cooperation among advertisers, a Distributed Coordinated Multi-Agent Bidding (DCMAB) is proposed.
- In marketing, the ability to accurately target an individual is very crucial. This is because the right targets obviously lead to a high return on investment. The study in this paper was based on Taobao — the largest e-commerce platform in China. The proposed method outperforms the state-of-the-art single-agent reinforcement learning approaches.
SHARE THIS



Discover More Tutorials
Delve into a variety of expert-led tutorials designed to deepen your understanding of AI, MLOps, reinforcement learning, and more. Gain practical insights, step-by-step guidance, and actionable skills to stay ahead in the rapidly evolving tech landscape.


Is Explainability critical for your AI solutions?
Schedule a demo with our team to understand how AryaXAI can make your mission-critical 'AI' acceptable and aligned with all your stakeholders.


AryaXAI provides the most accurate explainability and alignment stack to deliver accurate, true-to-model explainability, monitoring, risk management, and alignment techniques essential for highly mission-critical or regulated AI solutions.
Address: 3828 Kennett Pike, Suite 212 Greenville, DE 19807-2331
Products
Resources
Follow Us



Get in touch